Hi, I'm Matthew
A Computer Science student who Machine Learning and Data!

A Computer Science student who Machine Learning and Data!
Hello, I’m Matthew, and I am a final-semester Computer Science student at Lublin University of Technology. I am an AI/ML Engineer and Data Scientist with a deep passion for developing machine learning and deep learning models. I focus on achieving a profound understanding of concepts, data preprocessing, analysis, feature engineering, hyperparameters, and architectures to design, build, and fine-tune models effectively and precisely. I have a strong affinity for mathematics and English and enjoy solving algorithmic problems, such as those found on LeetCode. I am particularly drawn to projects involving complex and intricate datasets that require a deep and comprehensive approach to creating accurate and well-optimized architectures and pipelines. My work reflects a strong commitment to advancing within the AI landscape.
Underneath you may find my technical & miscellaneous skills
Additionally, I have experience with C++, Java, HTML, CSS, JavaScript, Swift, and PHP, and mainly work on Linux and Windows operating systems.
I utilize these platforms in my daily workflow for efficient machine learning and software development, enabling structured experimentation, clean code management, and scalable project organization.
Beneath, you may find a selection of projects that I have worked on.
This large-scale project features an advanced Retrieval-Augmented Generation (RAG) system built within a RESTful API architecture. It leverages a dual-backend design with Django for user and PostgreSQL database management, and FastAPI for RAG logic within isolated containers to ensure modularity and scalability. The Angular-based frontend integrates seamlessly with both backends, providing a dynamic and responsive interface. Fully dockerized and CI/CD-ready via Jenkins, the system is currently being deployed to Azure Kubernetes Service (AKS), with Prometheus and Grafana monitoring planned for live production environments.
Explore this project on GitHub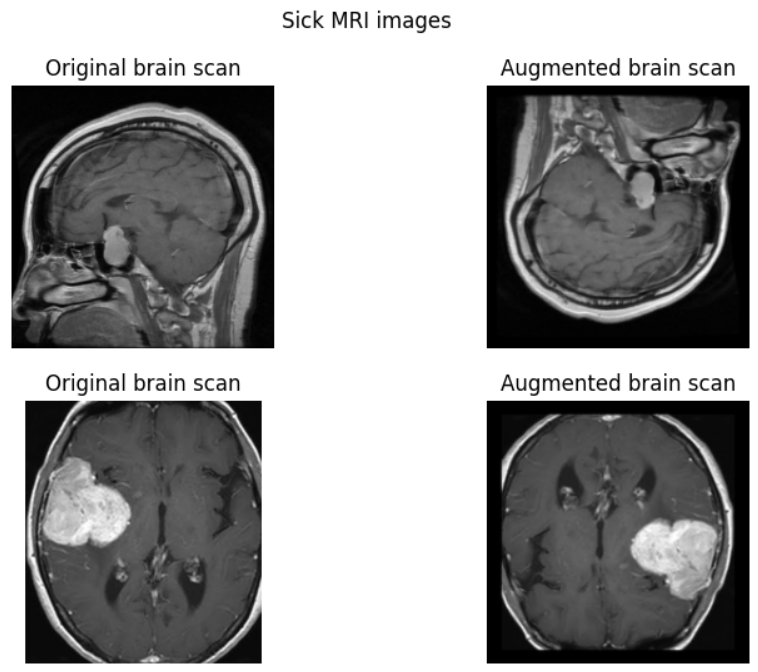
This brain tumor prediction model harnesses a fine-tuned CNN architecture, leveraging extensive data augmentation and rigorous preprocessing to achieve over 96% accuracy. Outperforming expert radiologists, it integrates advanced deep learning techniques with meticulous optimization to reliably detect and classify tumors. Designed for precision and efficiency, this model serves as a powerful diagnostic tool, supporting early detection and informed medical decisions in critical healthcare scenarios.
Explore this project on GitHub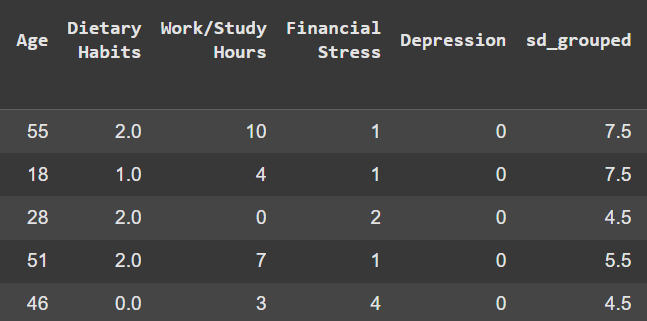
The Depression Predicting Model is a machine learning model that predicts whether a person has depression. It is implemented with scikit-learn and designed to make predictions based on various input features, carefully adjusted and refined. It employs robust preprocessing, data analysis, PCA, and feature engineering, combined with an SVM model, due to the high dimensionality and nature of the data. This is broad yet straightforward approach makes it well-suited for tabular datasets with moderate complexity, ensuring slight interpretability while leveraging the power of SVM, which is well-suited for this binary classification task.
Explore this project on GitHub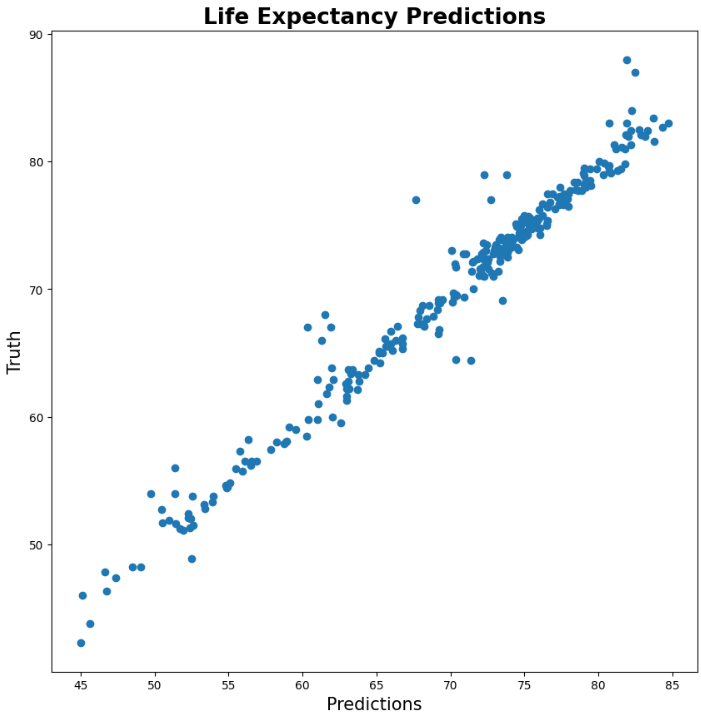
The Life Expectancy Model is a deep learning model implemented in TensorFlow, designed to predict life expectancy based on various input features. The data was carefully adjusted and refined for the problem before the model was created. It employs a relatively shallow architecture with a few dense layers and uses the Adam optimizer for efficient, adaptive gradient descent, minimizing a linear regression loss to closely align predictions with actual values. The model achieves excellent regression performance, with an average prediction error of approximately ±1.2 years, and with good confidence intervals, which is a competetive result.
Explore this project on my GitHub
This is the prepared dataset to predict whether the person died or survived the Titanic disaster for a Kaggle competition. The code is highly flexible and includes hints at each step, allowing you to make modifications as needed. Additionally, it is provided as a notebook, so you can experiment with the code before using the dataset for ML/DL tasks. It covers data engineering, preprocessing, and adjustments tailored to ML and DL architectures, complete with detailed annotations.
Explore this project on GitHubHere are some of my work experiences so far.
A blog is currently in development. It will feature insights, experiences, and knowledge-sharing on the topics of machine learning, and on the architectures of the deep learning models.